mjlab and GPU-Accelerated Reinforcement Learning
Contents
Table of Contents
▼
I recently went down a technical rabbit hole exploring mjlab, a new open-source framework that is quietly solving one of the biggest headaches in robotics reinforcement learning (RL): the trade-off between performance and usability.[*](Software reference: MJLab: Isaac Lab API, powered by MuJoCo-Warp by Kevin Zakka, Brent Yi, Qiayuan Liao, and Louis Le Lay (2025).)Existing tools often force a choice. You can have excellent RL abstractions (like Isaac Lab) but suffer through heavy, monolithic installations. Or, you can have raw speed (like MJX) but deal with steep learning curves and collision scaling issues.[*](Comparative frameworks: Isaac Lab by NVIDIA and MJX by Google DeepMind.)
mjlab attempts to hit the sweet spot. It combines Isaac Lab's proven manager-based API with MuJoCo Warp, a GPU-accelerated physics engine. The result is "bare metal" performance with a developer experience that actually feels modern.
I wanted to test if this promise held up. My goal was to take a Unitree G1 humanoid and train a custom policy to stand still—building the task, training the network, and deploying the result entirely within this new ecosystem.
The Architecture: Why mjlab is Different
Before writing code, I dug into how mjlab is structured. It's not just a wrapper; it's a re-architecture of the simulation loop.
- The Physics: It uses MuJoCo Warp to run thousands of environments in parallel on the GPU. Unlike standard MuJoCo (CPU-bound), this allows for massive throughput without the overhead of USD-based pipelines.
- The Abstraction: It adopts a "Manager-Based" architecture. Instead of writing a monolithic environment class, you compose tasks using Managers (Observation, Reward, Action).
- The Tooling: It relies on
uvfor package management. This might seem minor, but installing the entire stack takes seconds, not hours.[*](Package management provided by uv, an extremely fast Python package installer and resolver.)
The Baseline: When Gravity Wins
I started by establishing a baseline. I wanted to see the Unitree G1's default behavior in the physics engine without any neural network stabilizing it.[*](Robot specifications available at Unitree Robotics G1 Humanoid.)
Using the play script with a random agent, I launched the native viewer:
uv run play Mjlab-Velocity-Flat-Unitree-G1 --agent random --viewer native
This visual confirms the challenge. The G1 has 29 degrees of freedom. Without a control policy, gravity takes over instantly. The simulation is running at 60FPS in the viewer, but under the hood, the physics stepper is handling contact dynamics that make "just standing up" a complex control problem.
Engineering the Task
To solve this, I didn't want to write a new environment from scratch. I leveraged the modular nature of mjlab.
The framework already has a Velocity task designed to make robots walk. I realized I could "hack" this task. By overriding the command generator to essentially request a velocity of 0.0 m/s across all axes, I could repurpose the walking logic into a balancing logic.
I created a custom configuration file src/mjlab/tasks/velocity/config/g1/standing.py. Here is the implementation:
from mjlab.tasks.velocity.config.g1.env_cfgs import unitree_g1_flat_env_cfg
from mjlab.tasks.velocity.rl import VelocityOnPolicyRunner
from mjlab.tasks.registry import register_mjlab_task
def unitree_g1_standing_env_cfg(play: bool = False):
# 1. Inherit the base configuration
cfg = unitree_g1_flat_env_cfg(play=play)
# 2. Constrain the Command Manager
# We override the velocity ranges to be strictly zero.
cfg.commands["twist"].ranges.lin_vel_x = (0.0, 0.0)
cfg.commands["twist"].ranges.lin_vel_y = (0.0, 0.0)
cfg.commands["twist"].ranges.ang_vel_z = (0.0, 0.0)
# 3. Force the "Standing" flag
# This ensures the reward manager prioritizes posture over movement.
cfg.commands["twist"].rel_standing_envs = 1.0
return cfg
# 4. Register the task via the Plugin System
register_mjlab_task(
task_id="Mjlab-Standing-Flat-Unitree-G1",
env_cfg=unitree_g1_standing_env_cfg(),
play_env_cfg=unitree_g1_standing_env_cfg(play=True),
rl_cfg=unitree_g1_ppo_runner_cfg(),
runner_cls=VelocityOnPolicyRunner,
)
This snippet highlights the elegance of the system. I didn't touch C++ code or raw physics arrays. I simply configured the Command Manager to align with my goal.
Under the hood, this configuration shifts the optimization landscape of the Reinforcement Learning agent. By setting the command , the tracking reward simplifies to a penalty on any movement:
Simultaneously, setting rel_standing_envs = 1.0 tightens the tolerance on the posture reward. In walking tasks, the robot is allowed to deviate from its default joint angles to achieve gait. In standing mode, the standard deviation is significantly reduced, forcing the policy to adhere strictly to the reference pose:[*](This exponential reward formulation is adapted from the Legged Gym framework. See: Rudin et al. (2021), "Learning to Walk in Minutes Using Massively Parallel Deep Reinforcement Learning".)
The combination of these two terms forces the policy into a "minimum energy" basin: it must stop moving () while maintaining a rigid structure () to maximize the cumulative reward.
The Training Stack (PPO on GPU)
With the task registered, I initiated the training loop. This is where mjlab flexes its muscle.
uv run train Mjlab-Standing-Flat-Unitree-G1 --env.scene.num-envs 4096
Under the hood, mjlab spins up 4,096 parallel environments on the GPU. It initializes a PPO (Proximal Policy Optimization) agent with an Actor-Critic network architecture (Layer sizes: 512 -> 256 -> 128).[*](Algorithm reference: Proximal Policy Optimization Algorithms by Schulman et al. (2017).)
Because the data never leaves the GPU (thanks to MuJoCo Warp), the iteration speed is blistering. The graph below shows the training progress.
We can clearly see the difference between a successful run (Blue) and a failed/early run (Pink) in the metrics:
We can also look at the hardware utilization to verify the "bare metal" performance claims. The GPU memory allocation plateaus instantly, indicating efficient pre-allocation.
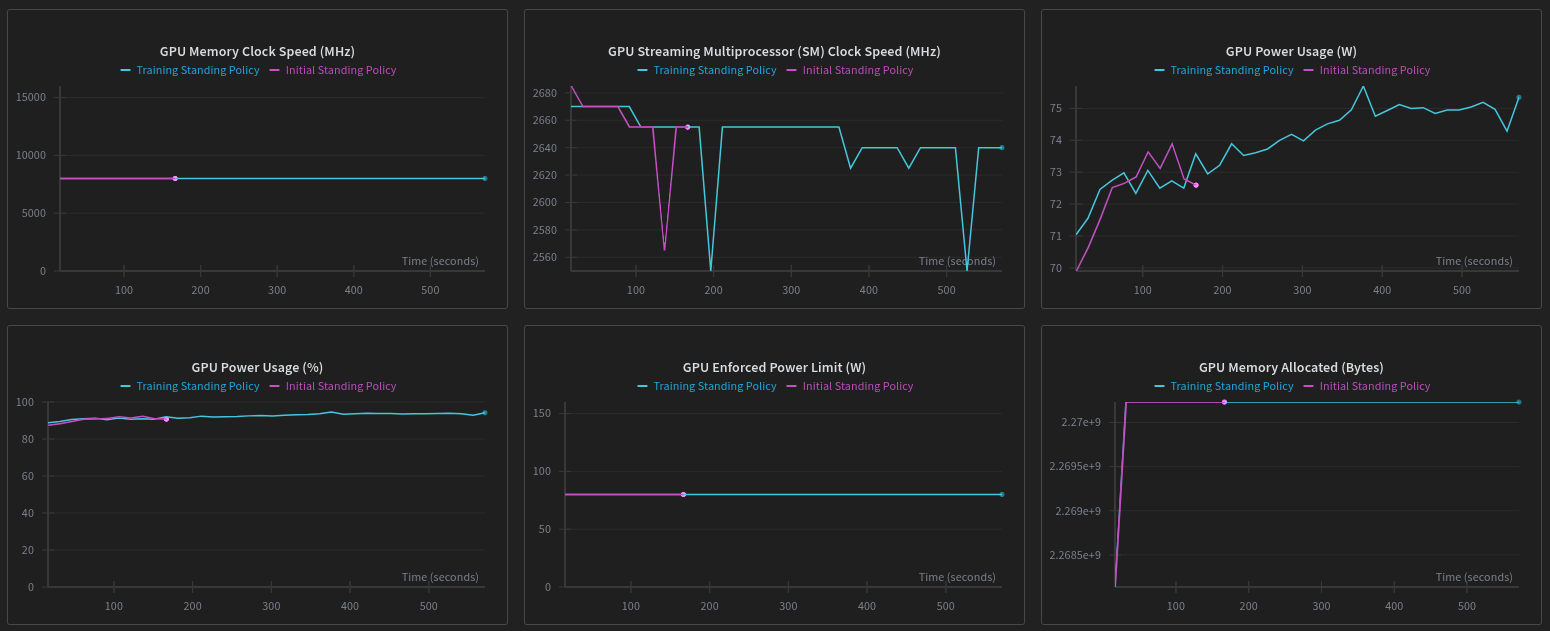
Analysis: You can see the distinct "knee" in the curve where the policy discovers the stable region. The reward signal transitions from minimizing falling penalties to maximizing posture rewards.
Intermediate Results: The "Wobbly" Phase
I interrupted the training early to inspect a checkpoint. I wanted to see what a "partially learned" policy looked like.
This state is fascinating. The robot has learned that "falling is bad," but it hasn't mastered the fine-grained motor control. We can actually see this failure mode in the telemetry of the Initial Standing Policy:
Final Deployment: A Stable Policy
After letting the training converge (150 iterations), I deployed the final policy using the native viewer.
uv run play Mjlab-Standing-Flat-Unitree-G1 \
--checkpoint_file logs/rsl_rl/g1_velocity/.../model_150.pt \
--viewer native
The difference is night and day. The policy has learned to effectively fight gravity with minimal joint movement. The native viewer allows us to visualize the contacts and forces in real-time, confirming that the robot is actively balancing, not just frozen in place.
Advanced Engineering Features
Beyond this specific task, my exploration revealed several advanced features that make mjlab production-ready for researchers:
The NaN Guard
One of the most frustrating parts of RL is numerical instability. mjlab includes a specialized NaN Guard that buffers simulation states. If a NaN or Inf is detected in qpos or qvel, it dumps the state to disk without pausing the simulation flow (to avoid spamming logs). You can then inspect the exact frame where the physics broke using uv run viz-nan.
Sim-to-Real: Domain Randomization
For a policy to work on a real robot, it needs robustness. mjlab supports domain randomization out of the box via EventTerm configurations. You can randomize parameters like geom_friction, body_mass, and actuator gains (kp, kd) directly in the config, ensuring the policy doesn't overfit to the simulation.
Custom Robot Support
While the framework comes with Unitree robots, importing custom hardware is straightforward provided you use the MJCF format. If you are coming from ROS/URDF, you will need to convert your models first.[*](For model conversion, MuJoCo Menagerie is the recommended resource for high-quality, pre-converted assets.)
Conclusion
mjlab represents a shift in how we approach sim-to-real workflows. By stripping away the bloat and focusing on the intersection of modern RL APIs and fast physics, it allows researchers to iterate in minutes rather than hours.
From a simple demo to a fully trained, stable humanoid policy, the friction was minimal—and the performance was undeniable.